
隨著全球經(jīng)濟(jì)格局的不斷變化與金融市場(chǎng)波動(dòng)的加劇,貴金屬因其獨(dú)特的避險(xiǎn)屬性和價(jià)值儲(chǔ)藏功能,日益成為投資者資產(chǎn)配置中不可或缺的一環(huán)。深圳,作為中國改革開放的前沿與經(jīng)濟(jì)創(chuàng)新的高地,匯聚了眾多專業(yè)的貴金屬投資與信息咨詢公司。這些機(jī)構(gòu)不僅為投資者提供了進(jìn)入黃金、白銀、鉑金、鈀金等市場(chǎng)的渠道,更以其深度的行業(yè)洞察和專業(yè)的專家咨詢支持,助力投資者在復(fù)雜的市場(chǎng)環(huán)境中把握機(jī)遇、管理風(fēng)險(xiǎn)。
一、 專業(yè)機(jī)構(gòu)的核心價(jià)值:超越交易的咨詢支持
深圳的貴金屬投資公司,其核心優(yōu)勢(shì)往往不僅在于提供交易平臺(tái)或產(chǎn)品,更在于構(gòu)建了一套涵蓋市場(chǎng)分析、投資策略、風(fēng)險(xiǎn)管理的全方位專家咨詢支持體系。這具體體現(xiàn)在:
- 深度市場(chǎng)研究與分析:專業(yè)團(tuán)隊(duì)持續(xù)跟蹤全球宏觀經(jīng)濟(jì)形勢(shì)、地緣政治動(dòng)態(tài)、央行貨幣政策及供需基本面,為客戶提供及時(shí)、深入的市場(chǎng)研究報(bào)告與趨勢(shì)研判,幫助投資者理解價(jià)格波動(dòng)背后的邏輯。
- 個(gè)性化資產(chǎn)配置方案:基于客戶的風(fēng)險(xiǎn)承受能力、投資目標(biāo)與財(cái)務(wù)現(xiàn)狀,專家顧問能夠提供量身定制的貴金屬配置建議。無論是用于長(zhǎng)期保值的實(shí)物金條,還是用于短期波段操作的賬戶貴金屬或衍生品,都能得到專業(yè)的配置指導(dǎo)。
- 風(fēng)險(xiǎn)管理與投資者教育:貴金屬市場(chǎng)同樣存在波動(dòng)風(fēng)險(xiǎn)。正規(guī)公司會(huì)強(qiáng)調(diào)風(fēng)險(xiǎn)揭示,并通過咨詢講座、線上課程、一對(duì)一輔導(dǎo)等形式,持續(xù)進(jìn)行投資者教育,幫助客戶樹立正確的投資理念,掌握基本的風(fēng)險(xiǎn)管理工具和方法。
- 全流程信息服務(wù):從開戶指導(dǎo)、交易軟件使用,到結(jié)算交割、資產(chǎn)報(bào)告,專業(yè)的咨詢支持貫穿投資全過程,確保客戶體驗(yàn)的流暢與信息的透明。
二、 深圳貴金屬投資的選擇要點(diǎn)
面對(duì)市場(chǎng)上眾多的服務(wù)機(jī)構(gòu),投資者在選擇深圳的貴金屬投資公司時(shí),應(yīng)重點(diǎn)關(guān)注以下幾個(gè)方面,以確保資金安全與服務(wù)專業(yè)度:
- 合規(guī)經(jīng)營是基石:首要確認(rèn)公司是否具備相關(guān)金融監(jiān)管機(jī)構(gòu)頒發(fā)的合法經(jīng)營資質(zhì),是否為上海黃金交易所、上海期貨交易所等正規(guī)市場(chǎng)的金融類或綜合類會(huì)員單位。
- 專家團(tuán)隊(duì)的實(shí)力:了解公司的研究團(tuán)隊(duì)背景、顧問的專業(yè)資質(zhì)與行業(yè)經(jīng)驗(yàn)。一個(gè)穩(wěn)定、資深的專家團(tuán)隊(duì)是提供高質(zhì)量咨詢服務(wù)的保障。
- 服務(wù)體系的完善度:考察其咨詢服務(wù)的渠道(如線上、線下、7x24小時(shí)支持)、內(nèi)容深度以及響應(yīng)速度。完善的服務(wù)體系能在關(guān)鍵時(shí)刻為客戶提供決策支持。
- 信息透明度與口碑:關(guān)注其市場(chǎng)分析報(bào)告的質(zhì)量、收費(fèi)標(biāo)準(zhǔn)的清晰度,并通過多方渠道了解市場(chǎng)口碑和歷史經(jīng)營狀況。
三、 貴金屬投資在當(dāng)代資產(chǎn)配置中的角色
在當(dāng)前低利率、高通脹預(yù)期及國際形勢(shì)多變的背景下,貴金屬的配置意義更加凸顯:
- 風(fēng)險(xiǎn)對(duì)沖工具:與傳統(tǒng)股票、債券資產(chǎn)的相關(guān)性較低,能在市場(chǎng)劇烈震蕩時(shí)起到有效的風(fēng)險(xiǎn)分散和對(duì)沖作用。
- 通脹抵御利器:歷史上,黃金等貴金屬長(zhǎng)期具有對(duì)抗貨幣貶值和通貨膨脹的能力。
- 長(zhǎng)期價(jià)值存儲(chǔ):貴金屬的稀缺性和物理屬性決定了其作為終極財(cái)富載體的長(zhǎng)期價(jià)值。
深圳的貴金屬投資與信息咨詢公司,正是連接投資者與這一重要資產(chǎn)類別的專業(yè)橋梁。通過借助其專業(yè)的專家咨詢支持,投資者可以更理性、更系統(tǒng)地將貴金屬納入投資組合,從而在追求財(cái)富保值增值的道路上,行穩(wěn)致遠(yuǎn)。
選擇一家提供強(qiáng)大專家咨詢支持的深圳貴金屬投資公司,意味著您選擇的不僅是一個(gè)交易通道,更是一位值得信賴的投資顧問和風(fēng)險(xiǎn)管家。在信息紛繁復(fù)雜的金融市場(chǎng)上,專業(yè)、精準(zhǔn)、及時(shí)的建議與支持,是做出明智投資決策的關(guān)鍵。建議投資者在行動(dòng)前,充分溝通、仔細(xì)比較,選擇最適合自身需求的合作伙伴,共同駕馭貴金屬市場(chǎng)的波瀾,實(shí)現(xiàn)資產(chǎn)的穩(wěn)健成長(zhǎng)。








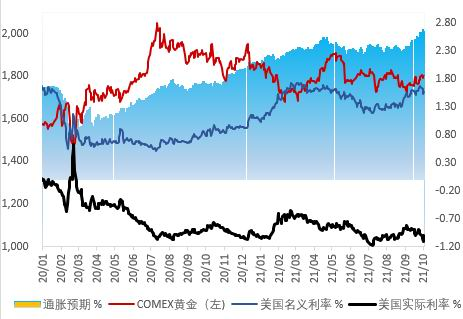 南非變異毒株擾動(dòng)市場(chǎng) 貴金屬預(yù)期震蕩偏強(qiáng) 投資咨詢?nèi)馕?/a>
南非變異毒株擾動(dòng)市場(chǎng) 貴金屬預(yù)期震蕩偏強(qiáng) 投資咨詢?nèi)馕?/a>