易觀國際 日本地震對軟件外包公司的短期影響分析
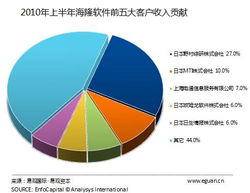
日本發生的地震事件對全球經濟產業鏈產生了不同程度的影響,其中軟件外包服務行業也受到了一定波及。易觀國際分析認為,日本地震對全球軟件外包公司,尤其是與日本有緊密業務往來的企業,在短期內可能帶來以下幾方面的影響:
項目交付進度可能面臨延遲。日本作為全球重要的軟件外包發包方之一,許多跨國軟件外包公司在日本擁有大量客戶和項目團隊。地震可能導致當地基礎設施受損、通信中斷以及人員安全與安置問題,進而影響項目的正常溝通、開發與測試流程,部分緊急項目可能需要重新協調資源與時間表。
短期內需求結構可能出現波動。日本企業在地震后可能將部分資源優先用于災后恢復與重建,非核心的軟件外包項目可能會被暫緩或調整優先級。這可能導致外包公司在短期內面臨訂單減少或項目變更的情況,尤其對于依賴日本市場的外包服務商而言,營收可能受到一定壓力。
第三,成本與運營風險上升。地震可能導致日元匯率波動、物流成本增加以及供應鏈中斷,這些因素可能間接推高外包公司的運營成本。為保障項目持續進行,部分公司可能需要增加遠程協作投入或調整團隊部署,進一步增加了管理復雜性與成本。
易觀國際也指出,這種影響可能是短期且結構性的。長期來看,日本在災后重建過程中可能加速數字化轉型,從而產生新的軟件外包需求,例如在基礎設施管理、應急系統開發、遠程協作工具等領域。外包公司若能靈活調整服務方向,積極適應客戶的新需求,有望在中期內抓住新的市場機會。
日本地震在短期內對軟件外包公司帶來了一定的運營與市場挑戰,但也可能催生新的服務需求。建議相關企業加強風險管理,優化遠程協作能力,并密切關注日本市場的恢復動態,以應對潛在的變化與機遇。
如若轉載,請注明出處:http://www.wisecloudpbx.cn/product/51.html
更新時間:2026-05-24 03:11:58